Admin Issues
Last Updated: May 10, 2022
Last Updated: May 10, 2022
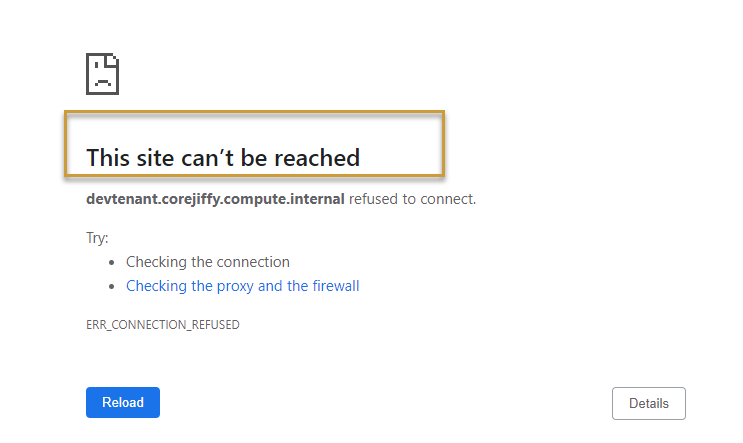
I am getting the error "Site cannot be reached" error for the Jiffyweb page.
ps -ef | grep -i nginx"
I am getting the error "500 Internal Server Error" for the Jiffyweb page.
supervisorctl status
application start all
ps -ef | grep -i postgres.
systemctl start postgresql-9.6
systemctl start postgresql-12
I am getting the error "502 Bad Gateway" after Jiffy login.
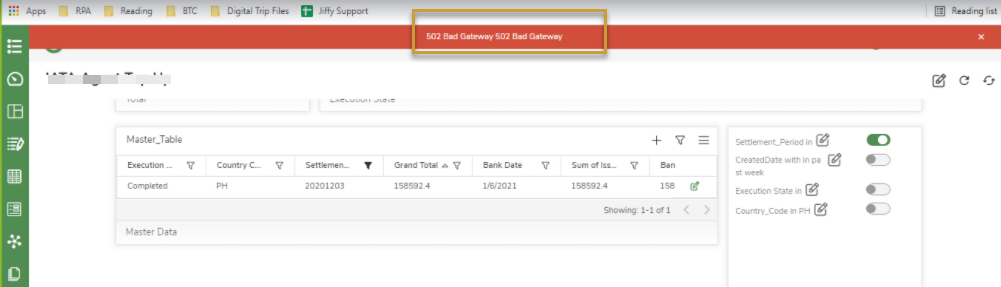 If this error shows once you log in to Jiffy Web, it may be due to Anthill is down/hung and GUS is unable to communicate with Anthill.
If this error shows once you log in to Jiffy Web, it may be due to Anthill is down/hung and GUS is unable to communicate with Anthill.
ps -ef | grep -i anthill
supervisorctl start anthill
supervisorctl stop anthill
kill -9 {pid}
supervisorctl start anthill
I am getting the error "Invalid Subdomain name" while logging into Jiffy.
 Invalid Subdomain name error occurs if:
Invalid Subdomain name error occurs if:
supervisorctl stop GUS
supervisorctl start GUS
select * from from tenants where tenant_name ='{configured_tenant_name}'; update tenants set sub_domain ='****' where id ='{tenant_id}';
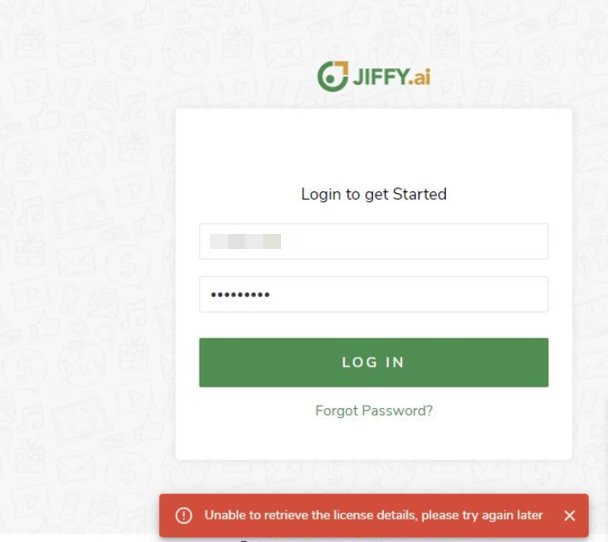
I am getting the error "Unable to retrieve license details" while logging into Jiffy.
I am getting the error "Could not create vault key" while using Secure Vault.
If it fails to show the status, it means vault is down, you can start the vault with command:vault status
Once the vault is up and sealed status is true(vault status), then you need to unseal the vault manually with vault keys that were shared during installation, using the below command.applicaition start vault
- $JIFFY_HOME/.vault.d/vault operator unseal {**********unseal_key_1****************}
- $JIFFY_HOME/.vault.d/vault operator unseal {**********unseal_key_2****************}
- $JIFFY_HOME/.vault.d/vault operator unseal {**********unseal_key_3****************}
vault token renew -increment={timetoLive} {AUTH_TOKEN}
After every server reboot, the vault needs to be started manually.
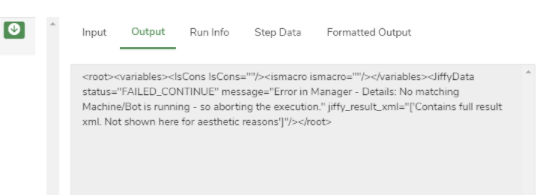
I am getting the error "No matching Machine/Bot running- so aborting execution" in Web UI node.
I am getting the error "Failed to parse data sent by Anthill component".
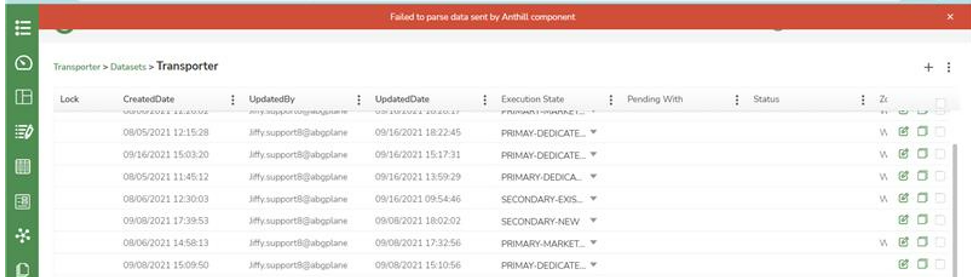 This issue happens when the anthill and mongo connectivity is broken.
Restart Core Application.
This issue happens when the anthill and mongo connectivity is broken.
Restart Core Application.
I am getting the error "HikariPool-1 - Connection is not available,request timedout after 30000ms" in Datasets.
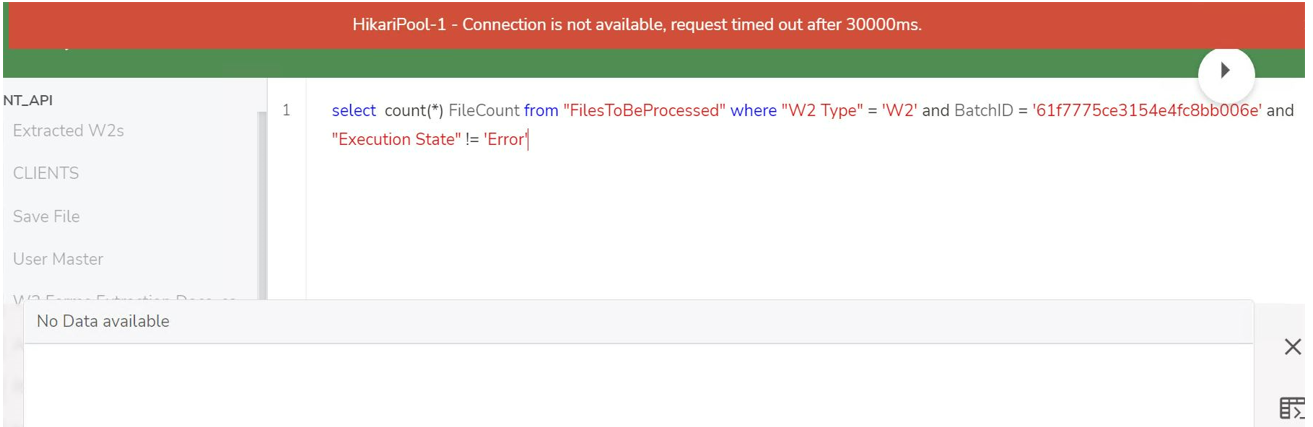 Sometimes the SQL queries would be querying too many records, causing the Drill to get hung. There are three processes that are inter-related Drill, zookeeper, and zeus.
Sometimes the SQL queries would be querying too many records, causing the Drill to get hung. There are three processes that are inter-related Drill, zookeeper, and zeus.
I am getting the error "SYSTEM ERROR:IllegalArgumentException:Attempted to send an message when connection is no longer valid. Query Submission to Drillbit failed".
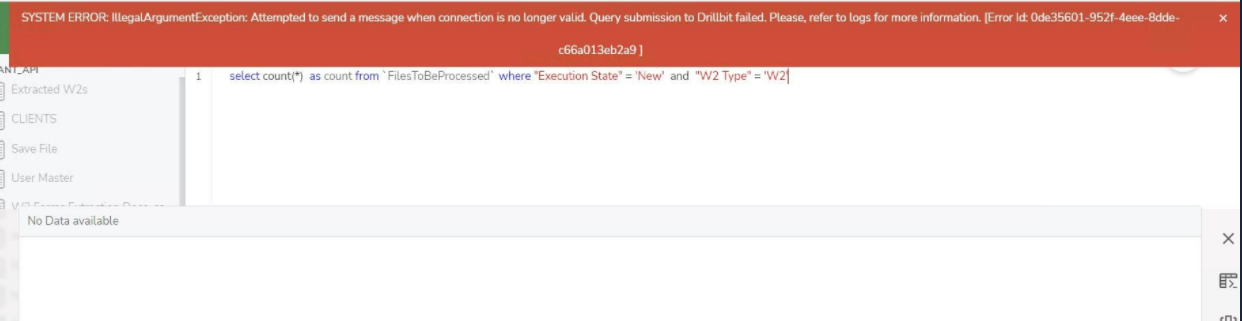 This issue happens when the drill goes down and there is too much memory consumed by drill.
This issue happens when the drill goes down and there is too much memory consumed by drill.
I am getting the error “Unable to reach jiffy server, please try after some time . If error persists, please connect Jiffy admin.” while saving task.
This issue occurs if any of the filesystem mount gets fully used.
I am getting the error "could not extend file "base/18276/19308.11": No space left on device" during task execution.
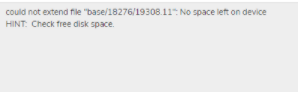 This issue happens when there is no space left on DB server.
This issue happens when there is no space left on DB server.
Technical Error While Familiarizing the Document using Doc Reader node
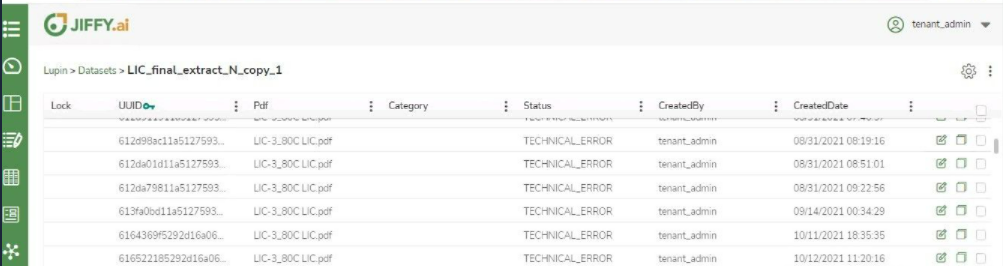
This may happen if the server.json file under /
I am getting the error as "System encountered an error" while logging into Jiffy.
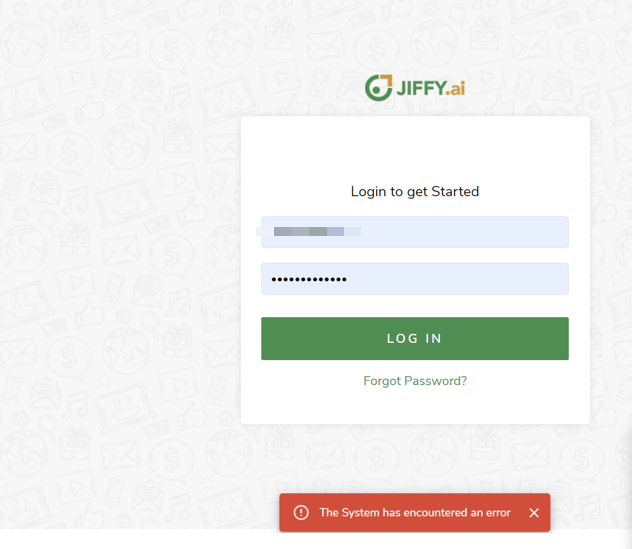 This happens when the redis process is down or when the redis certificates are expired. Check for redis certificate expiry.
This happens when the redis process is down or when the redis certificates are expired. Check for redis certificate expiry.
I am getting the error "java.lang.NullPointerException" while using Doc Reader node.
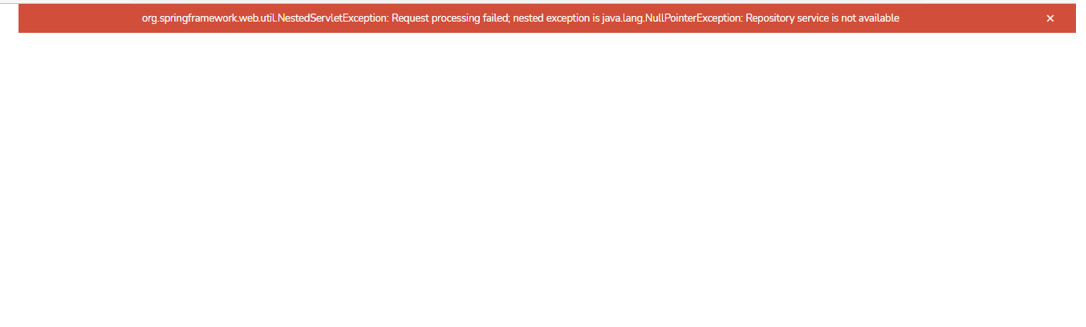 This happens when the server is upgraded and the client is still in old version.
This happens when the server is upgraded and the client is still in old version.
Execution Bot in "Not Available" Status. This issue happens when the Utang process goes out of memory. You can check the Coral/Zeus logs for out_of_memory errors. If you find any error in logs for out_of_memory, restart the Utang process from the Core server and restart the bot.
I am getting the error "504 gateway timeout" in Jiffy Web page. This issue happens when there is too much memory utilization on one of the processes Anthill, Mangrove, Coral, Oreng.
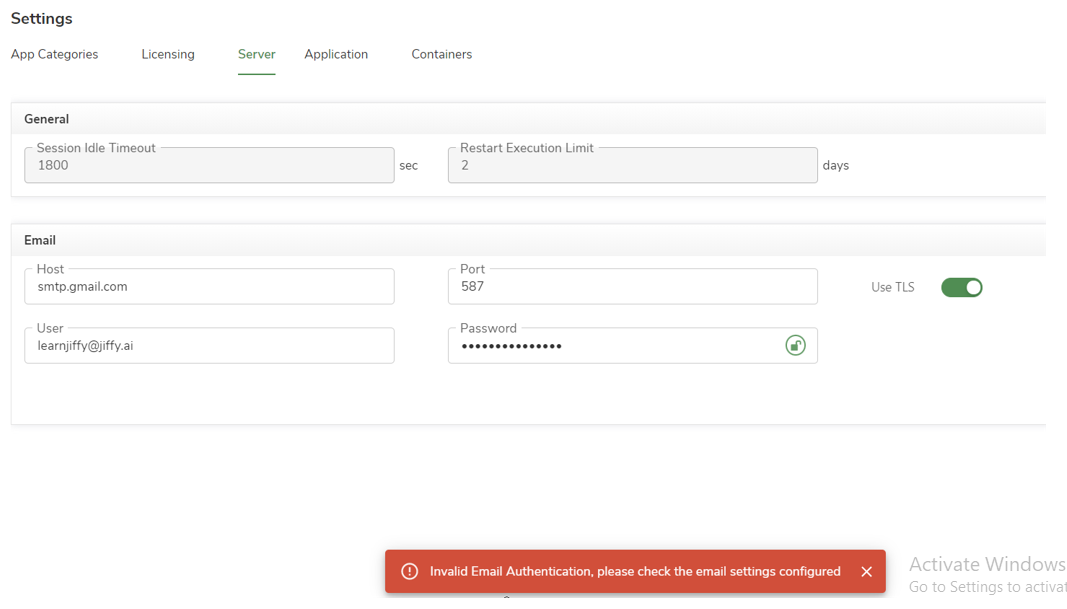
I am getting the error "Invalid Email Authentication, please check the email settings configured" while configuring Email settings.
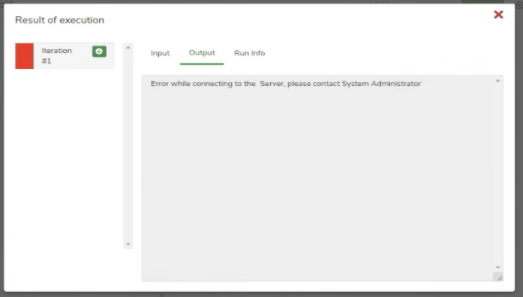
I am getting error "Error while connecting to the server" while using Doc reader node.